什么是算法?
Youtube 视频 - Algorithms and Data Structures Tutorial - Full Course for Beginners
算法可以理解为达成某个任务的步骤。例如如下任务:
- 图书馆里找书
- YouTube 上搜索视频
- Facebook 上搜索用户
搜索方式
- 线性搜索(Linear Search):按照顺序一个一个查找、对比、确定结果
- 二分搜索(Binary Search):上来就从中间查找目标、对比、确定向左还是向右继续二分……如此这般,最后确定结果
搜索效率
搜索的效率可以分为:算法的空间复杂度和时间复杂度。
- 空间
- 时间
时间复杂度(Time Complexity)
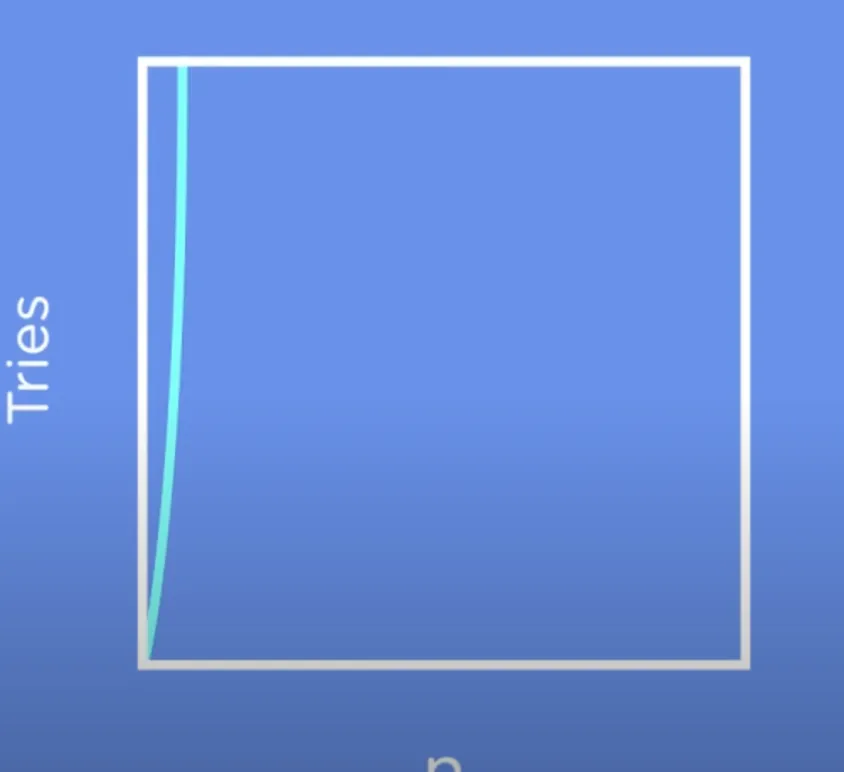
在 10000 个数字中找到目标,y 轴表示尝试的次数,x 轴表示目标值。
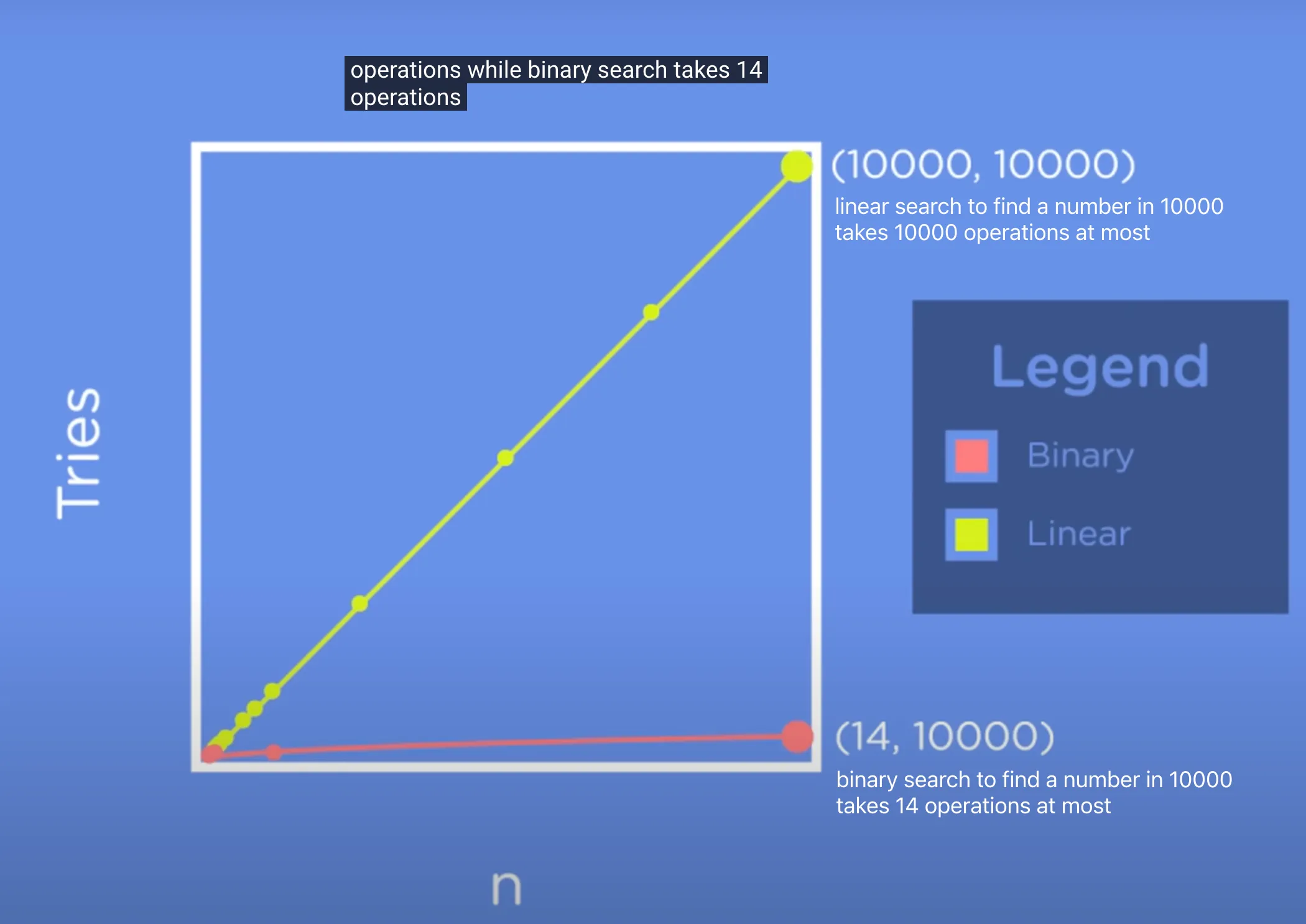
如上图,同样是找到 10000 这个数字,线性搜索需要执行 1w 次,但是二分搜索只要 14 次。前者所耗费时间是后者的 714 倍。
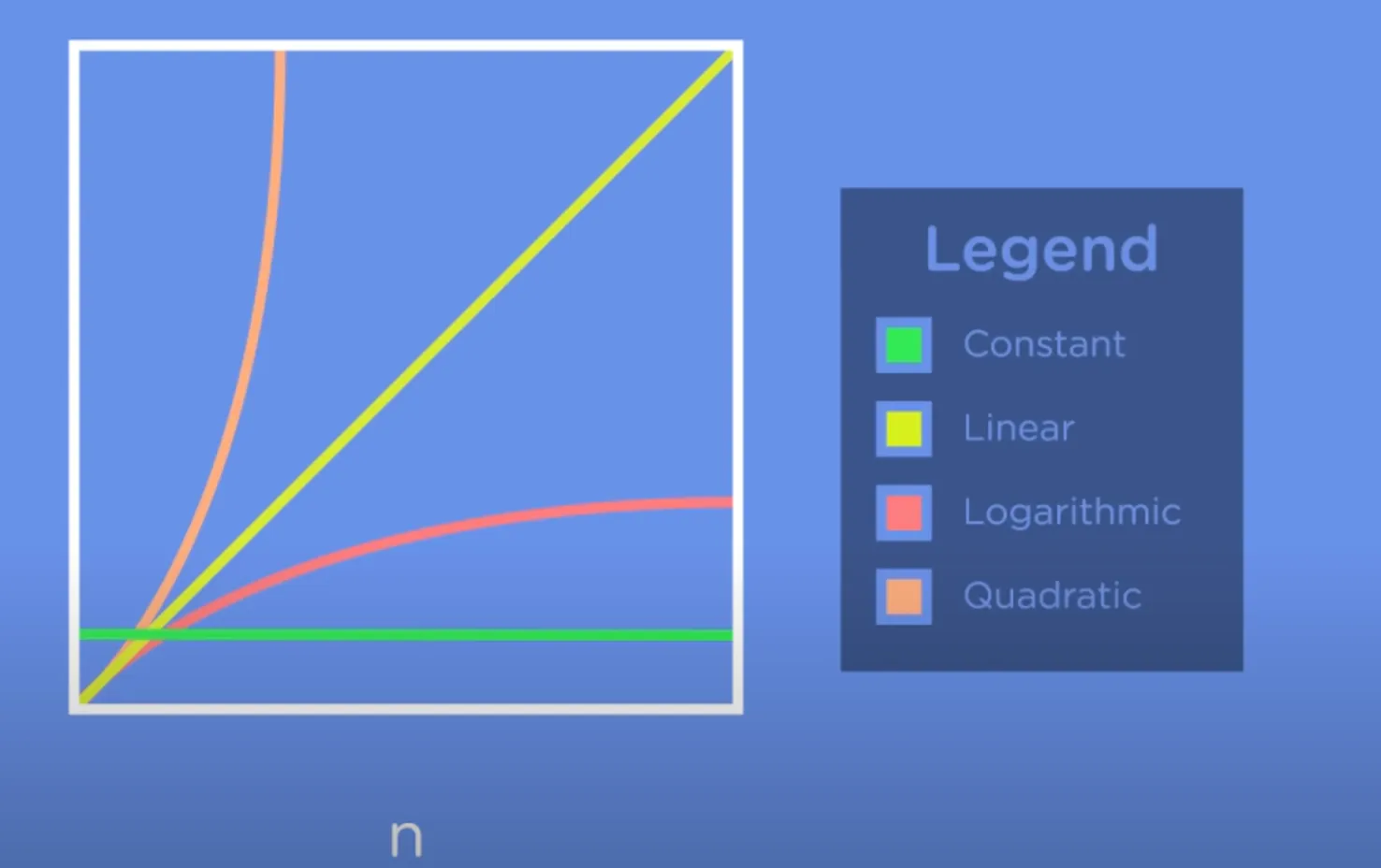
Big O
一个算法的复杂度描述方式。
O(n)
线性搜索
O(log n)
有对数:log2^8 = 3 含义:2 乘了多少次到达 8?3 次。
二分搜索,对数运行时间
O(n^2)
平方运行时间

O(n log n)
归并排序(Merge Sort),是针对数组的一种排序,n 为数组长度。点击 👉 十大经典排序算法(动图演示) 看动图
主要思想:将待排序的数组分割成若干个子数组,然后对每个子数组进行排序,最后将排序好的子数组合并,从而得到完全排序的数组。
具体步骤如下:
- 分割:将待排序的数组递归地分割成两个子数组,直到每个子数组的长度为1或者为空。
- 排序:对每个子数组进行排序。可以采用递归地应用归并排序算法来排序子数组
- 合并:将排序好的子数组合并成一个大的有序数组。合并过程是通过比较两个子数组的元素,并按照顺序将它们逐个放入一个临时数组中来完成的。
归并排序的关键在于合并过程,合并时需要比较两个子数组的元素,并按照顺序将它们放入临时数组中。合并完成后,临时数组中的元素就是按照从小到大的顺序排列的。最后,将临时数组中的元素复制回原始数组的对应位置,排序过程就完成了。
归并排序的时间复杂度是 O(n log n),其中 n 是待排序数组的长度。这使得归并排序成为一种高效的排序算法,尤其适用于大规模数据的排序。此外,归并排序是一种稳定的排序算法,即相等元素的相对顺序在排序后保持不变。
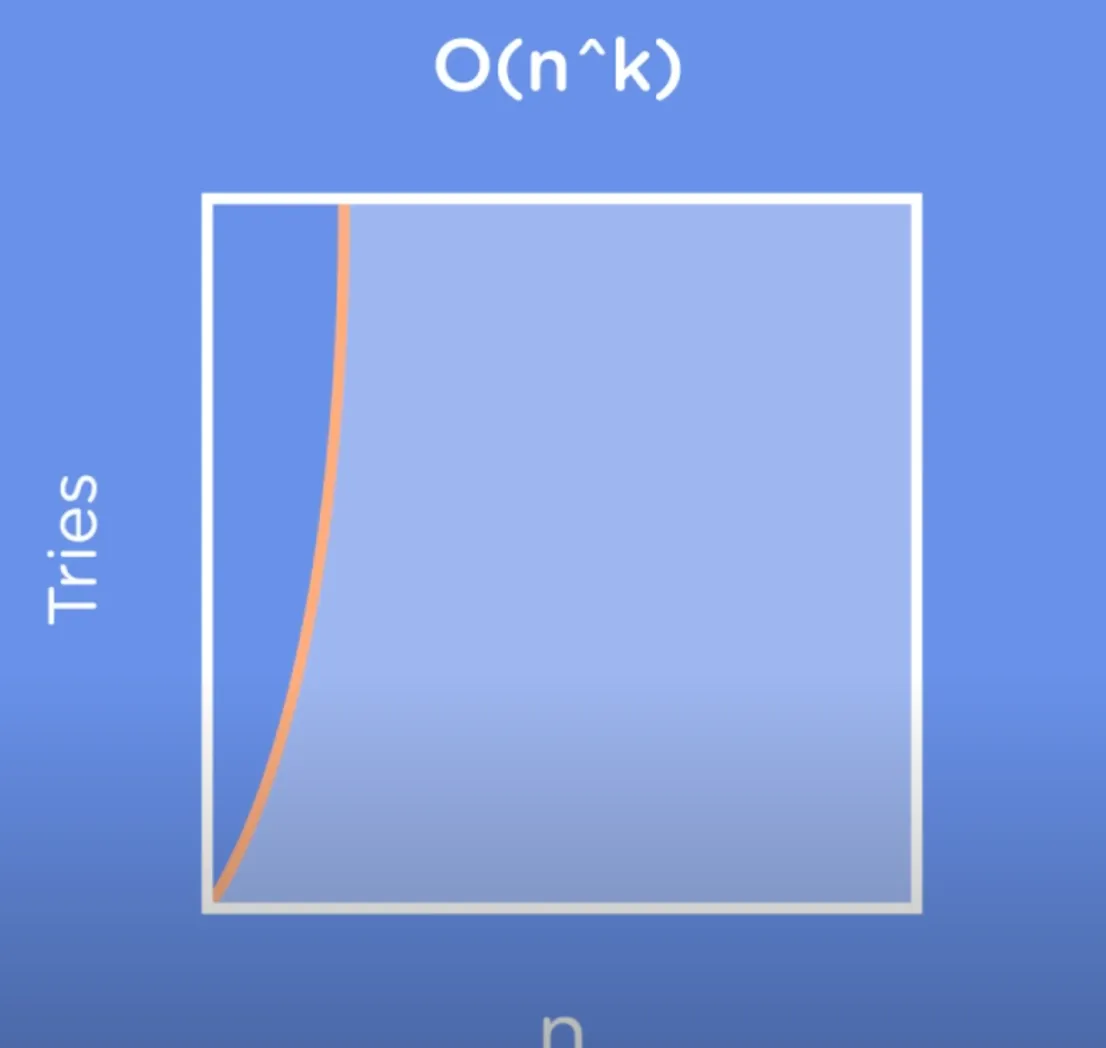
O(n ^ k)
糟糕的算法。
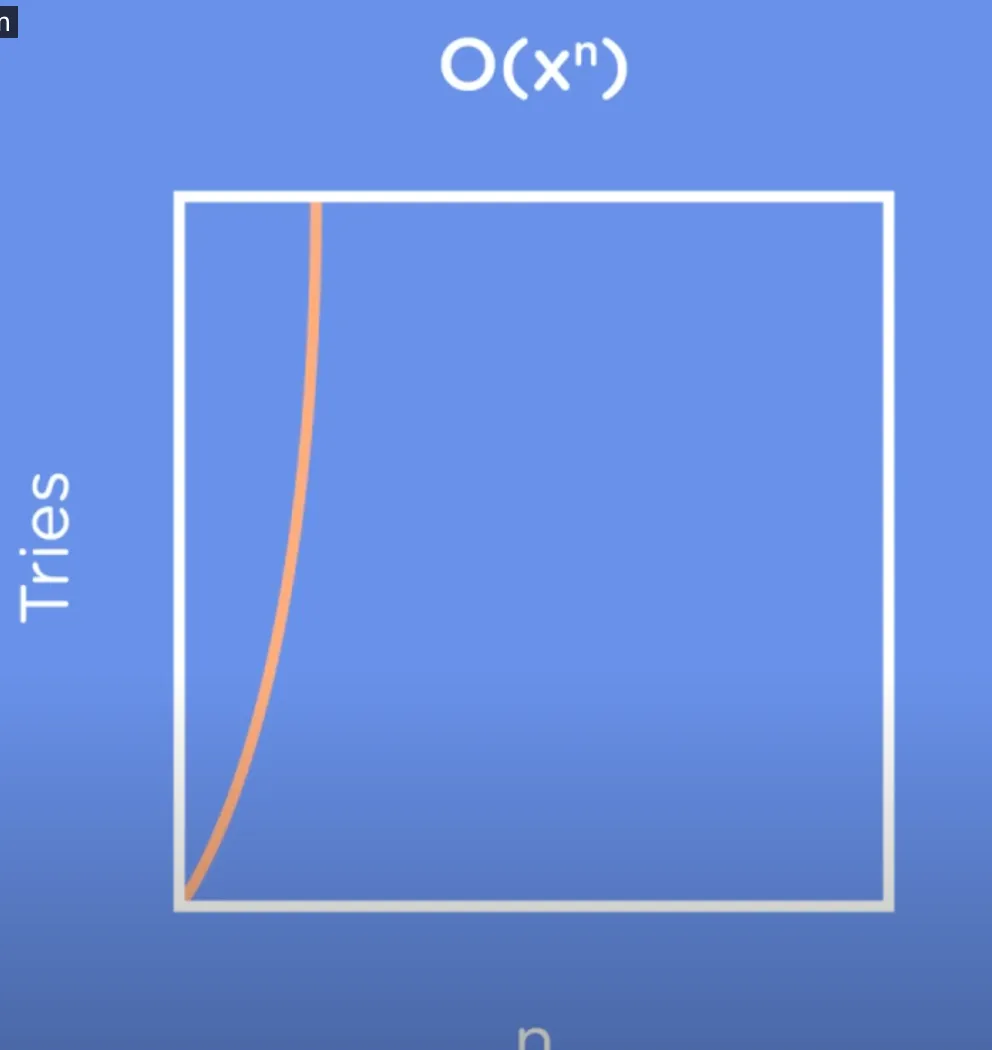
O(x ^ n)
糟糕的算法。
开锁:
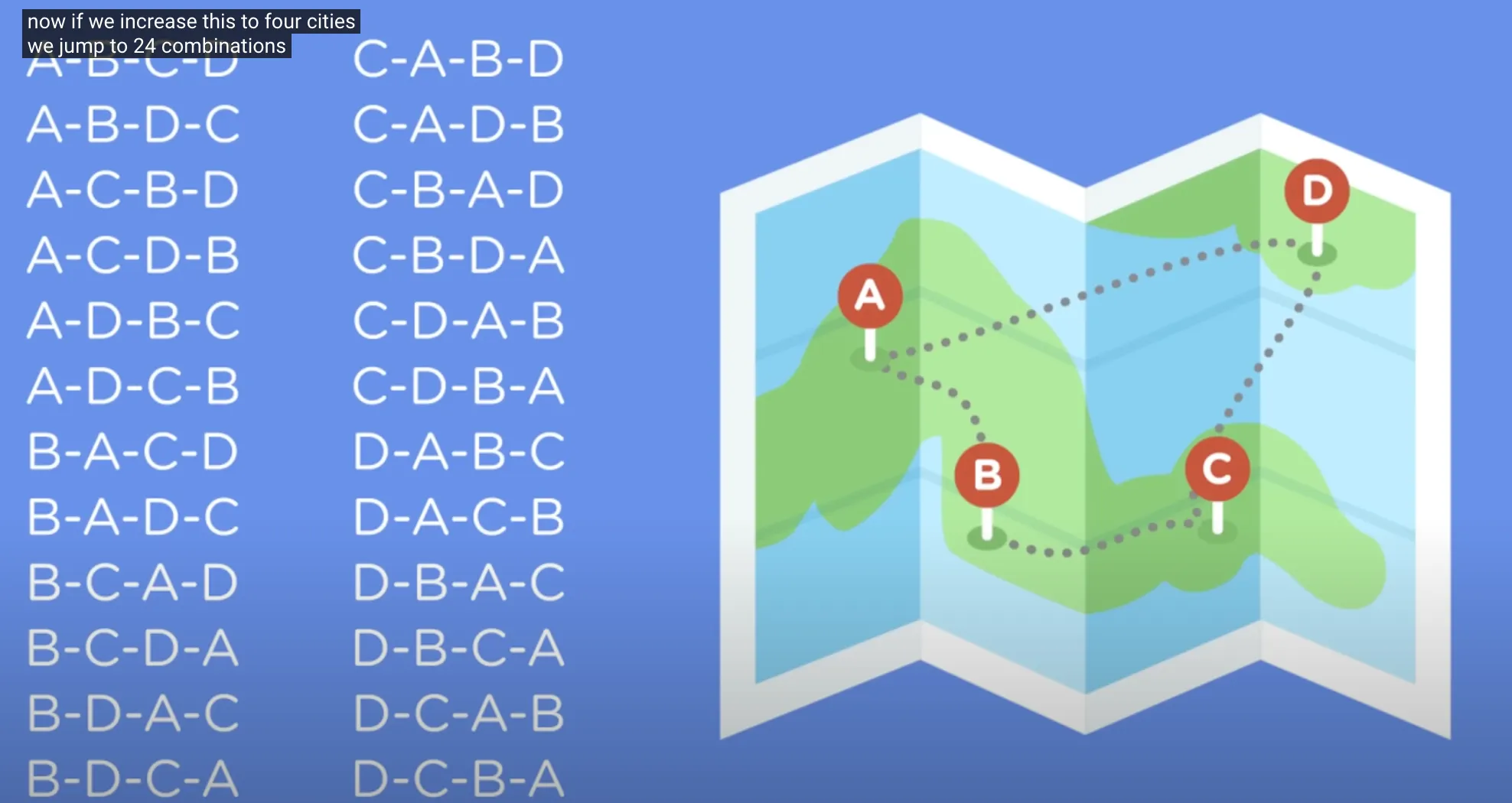
O(n!)
糟糕的算法。
设计旅游路线:
小结
- 给定一个数组,对于知道位置的元素(假设在第五个)的时间复杂度简化为 O(1)
- 对于未知的元素,需要一直找到底,O(n)
- 第二种方式比较慢,如果一开始从中间找,然后判断大小,再确定向左还是向右继续找,这种二分的方式的时间复杂度为 O(log n)
代码中的算法
linear search
# 线性搜索
def linear_search(list, target):
# for item in list:
for i in range(0, len(list)):
if list[i] == target:
return i
return None
def verify(index):
if index is not None:
print("Target found at index: ", index)
else:
print("Target not found in list.")
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
result = linear_search(numbers, 12)
verify(result)
result = linear_search(numbers, 6)
verify(result)binary search
def binary_search(list, target):
first = 0 # 头
last = len(list) - 1 # 尾
while first <= last:
# 找到中间值
# JS 代码:const mid = left + Math.floor((right - left) / 2);
midpoint = (first + last)//2
if list[midpoint] == target:
return midpoint
elif list[midpoint] < target:
first = midpoint + 1 # 左边界变成中间位置的后一个位置
else:
last = midpoint - 1 # 右边界变成中间位置的前一个位置
return None
def verify(index):
if index is not None:
print("Target found at index: ", index)
else:
print("Target not found in list.")
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
result = binary_search(numbers, 12)
verify(result)
result = binary_search(numbers, 6)
verify(result)
def binary_search(list, target):
first = 0 # 头
last = len(list) - 1 # 尾
while first <= last:
# 找到中间值
# JS 代码:const mid = left + Math.floor((right - left) / 2);
midpoint = (first + last)//2
if list[midpoint] == target:
return midpoint
elif list[midpoint] < target:
first = midpoint + 1 # 左边界变成中间位置的后一个位置
else:
last = midpoint - 1 # 右边界变成中间位置的前一个位置
return None
def verify(index):
if index is not None:
print("Target found at index: ", index)
else:
print("Target not found in list.")
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
result = binary_search(numbers, 12)
verify(result)
result = binary_search(numbers, 6)
verify(result)recursive binary search
# 递归的二分法
def recursive_binary_search(list, target):
if len(list) == 0:
return False
else:
midpoint = (len(list))//2
if list[midpoint] == target:
return True
else:
if list[midpoint] < target:
return recursive_binary_search(list[midpoint+1:], target)
if list[midpoint] > target:
return recursive_binary_search(list[:midpoint], target)
def verify(result):
print("Target found: ", result)
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
result = recursive_binary_search(numbers, 12)
verify(result)
result = recursive_binary_search(numbers, 6)
verify(result)递归(Recursion)和空间复杂度(Space Complexity)
递归
在函数体内部调用了自己,至少需要设置一个停止的条件。
空间复杂度
空间复杂度是算法在执行过程中所需的额外空间的量度。它用于衡量算法在解决问题时所占用的内存空间。
在分析算法的空间复杂度时,通常考虑以下几个方面:
输入空间:算法所需的输入数据所占用的空间。对于某些算法,输入空间的大小可能会对算法的空间复杂度产生影响。
辅助空间:算法在执行过程中使用的额外空间,不包括输入数据本身的空间。辅助空间包括算法中使用的临时变量、指针、栈空间、堆空间等。这些额外空间的使用可能是为了存储中间结果、递归调用的参数和返回地址、动态分配的内存等。
输出空间:算法产生的输出数据所占用的空间。有些算法可能会在原地修改输入数据,而不需要额外的输出空间。但是,对于那些需要输出结果的算法,其输出空间也会对空间复杂度产生影响。